Consistent Hashing: Scalable Routing for Distributed Systems
Introduction
Scaling systems always reminds me of training in the gym. When one muscle takes the entire workload, it burns out. Spread the load properly and everything becomes smoother, stronger, and more resilient.
Distributed systems are no different. Modern applications push terabytes of traffic and billions of keys across clusters that change constantly — servers fail, new nodes join, and traffic patterns spike unpredictably. If load isn't distributed intelligently, systems break fast.
Consistent hashing is a core mental model for engineers and architects. Whether you're scaling microservices, designing data stores, implementing queues, or operating cache layers, consistent hashing helps keep systems balanced and predictable.
The problem: why traditional hashing fails
Common approach:
serverIndex = hash(key) % N
Where N is the number of servers. This approach only works when N is static. In real clusters N changes frequently. Removing or adding a single server changes the modulo and causes:
- Almost all keys to remap because the modulo changes
- Rebalancing storms
- Latency spikes
- Hot partitions
We need a hashing strategy where server changes cause minimal disruption.
Consistent hashing: the foundation
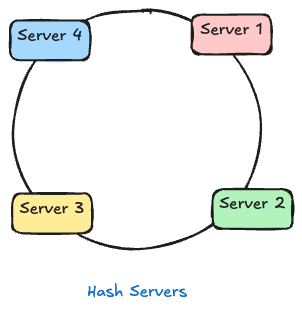
Consistent hashing maps servers and keys onto the same circular hash space (the ring). Rules:
- Hash servers and place them on the ring
- Hash keys and place them on the same ring
- Assign a key to the first server clockwise from the key's position
- When servers join/leave, only nearby keys move
This preserves stability and minimizes unnecessary key movement.
Hash function
Hash functions produce a numeric output inside a fixed range.
For example, SHA-1 outputs a 160-bit number: This range is called the hash space.
Instead of treating it like a long line, we wrap the ends together to form a ring.
This makes “clockwise lookup” natural and allows:
- wrap-around
- deterministic movement
- simple successor logic
Every server and key lands at a specific point on this ring.
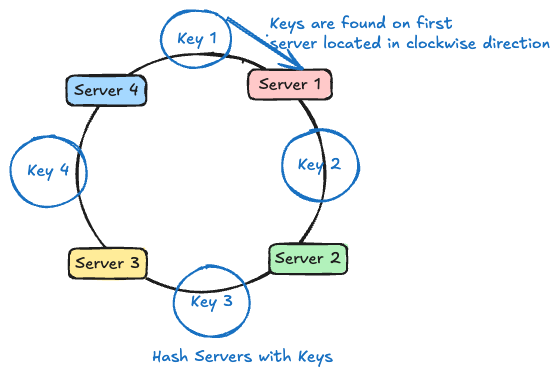
The real problem: uneven ring distribution
Consistent hashing helps, but two issues appear when you assign only one point per server:
1) Uneven server spacing
Hashing servers once can produce uneven gaps. One server might own 5% of the ring while another owns 45% — producing hotspots.
2) Large fault domains
If a server covers a large arc, removing it forces many keys to move, causing large-scale rebalancing.
Virtual nodes (vnodes): the solution
Virtual nodes represent each physical server multiple times on the ring. Instead of a single token per server, give each server many vnodes (e.g., 64–256 each).
Benefits:
- Smooth distribution (law of large numbers)
- Smaller migration chunks when adding/removing nodes
- Ability to weight nodes by capacity
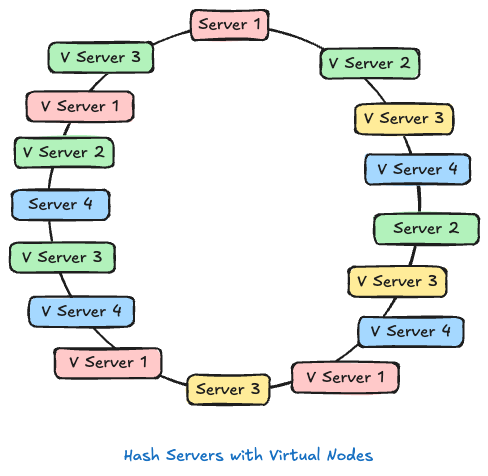
How vnode tokens are generated (practical)
Each vnode is typically given a token computed from the server's stable identifier plus a small replica index. For example:
token = hash(serverId + ":" + vnodeIndex)
Implementation tips:
- Use a deterministic serialization for serverId (UUID, IP:port, or a stable name).
- Generate vnodeIndex from 0..(V-1) for V vnodes per server. If you want to weight a server, give it more vnode indices.
- Store tokens sorted in a ring-ordered data structure (sorted array or balanced tree) and use binary search to find the first token >= keyHash (wrap to start if none).
- Handle rare token collisions by incrementing the index or using a secondary hash; collisions are rare with 64-bit hashes but plan for them.
This approach ensures vnode placement is deterministic and easy to recompute when servers join/leave.
How keys move when a server joins or leaves
- Adding a server affects only the small arcs behind its vnodes.
- Removing a server reassigns only the keys for its vnodes.
A Note on Replicas (Without Going Deep)
Most real distributed systems don’t store a key on just one server. They keep a few replicas for durability and availability. Consistent hashing helps here too — not by changing the algorithm, but by making replica selection predictable.
The idea is simple:
Once a key’s primary server is found, the next few servers clockwise on the ring become its replicas.
This keeps placement deterministic without requiring a central coordinator, which is why systems like DynamoDB and Cassandra build their replication strategies on top of consistent hashing.
(Replication itself is a deeper topic — consistency levels, conflict resolution, hinted handoff, repairs — and deserves its own article. Here, it’s enough to understand that consistent hashing provides a stable foundation for replica placement.)
Real-world systems that use these ideas
- Amazon DynamoDB — partitioning + replication
- Apache Cassandra — token ring
- Discord — session routing
- Akamai CDN — edge cache distribution
- Google Maglev — stable load balancing at hyperscale
These systems either implement vnode-style hashing or use managed partitioning that follows similar principles.
Fitness parallels
- VNodes = muscle fibers distributing load
- Smooth key movement = controlled progression
- Even distribution = balanced training
- Avoiding hot partitions = avoiding overuse injuries
Conclusion
Consistent hashing with vnodes provides predictable, low-churn scaling. Use stable node IDs, weight vnodes for capacity, and automate graceful rebalancing to keep systems resilient — much like consistent, well-structured training keeps bodies resilient.