RAG 101: Why Retrieval-Augmented Generation Matters (with a Fitness Twist)
When I committed to fitness, I realized something simple:
👉 Progress isn’t about guessing, it’s about tracking and using the right data.
Large Language Models (LLMs) are the same. They’re impressive, but let’s be honest:
❌ They hallucinate.
❌ They don’t know your context.
❌ They can’t read your workout logs or your Huberman notes.
That’s where Retrieval-Augmented Generation (RAG) comes in.
Think of RAG as giving AI your training logbook. Instead of inventing answers, it looks up your actual data before responding.
🔹 Why RAG Matters (Fitness Example)
Ask GPT: “How much protein should I eat?” → you’ll get a generic, textbook answer.
Ask via RAG, connected to your Google Sheets workout log + Huberman transcript:
- “You logged 135g protein daily on average last week.”
- “Huberman recommends 1.6–2.2g/kg body weight.”
One answer is theoretical.
The other is personal, grounded, and useful.
🔹 The Basic RAG Pipeline
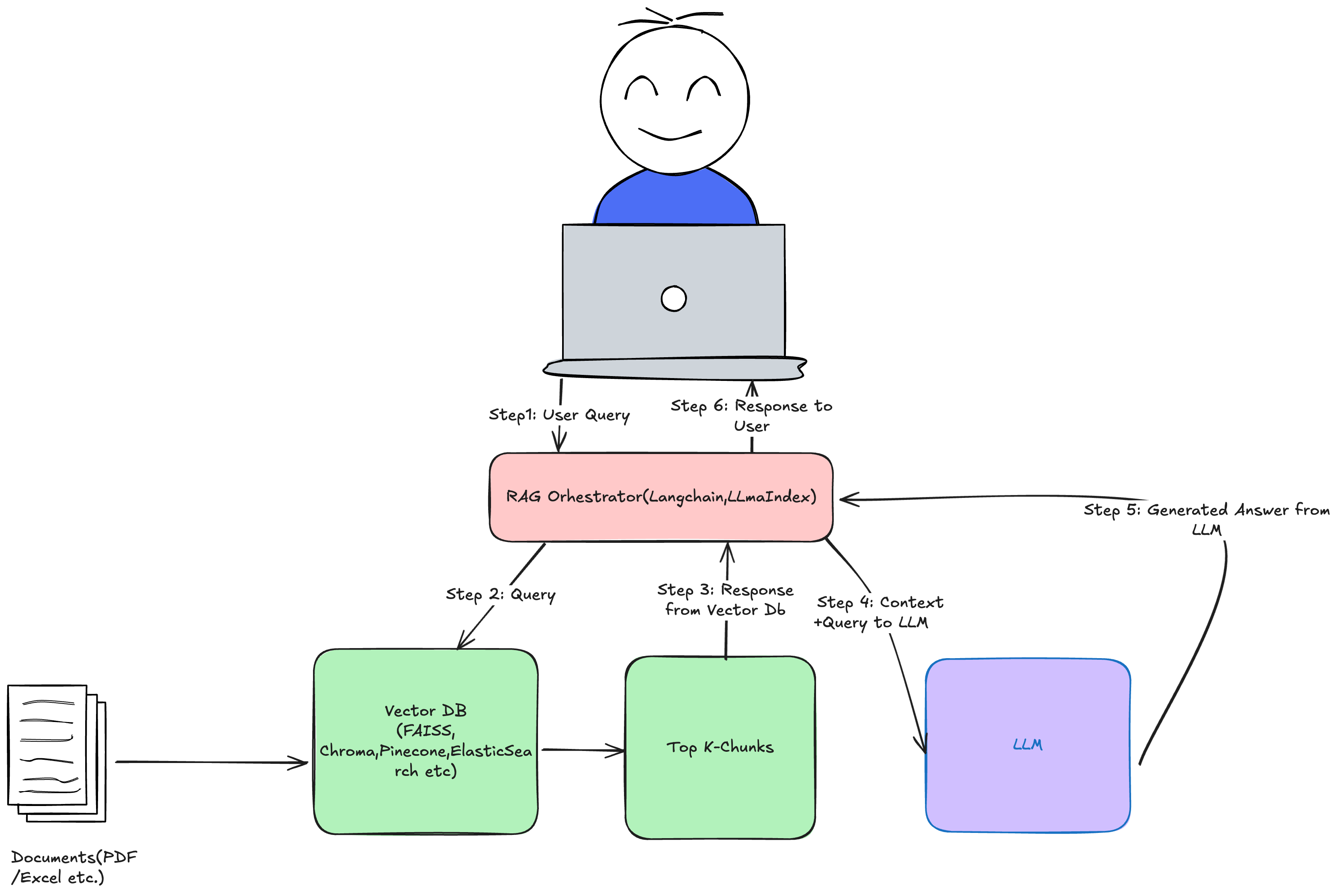
Fitness analogy:
- Vector DB = your workout notebook.
- LLM = your coach.
- Orchestrator = you, flipping to the right page before asking the coach what to do.
🔹 POC: Diet Chart Query System
I built a simple, local RAG demo that lets you query your own PDF (like a diet plan or fitness log) using LangChain, Ollama, and ChromaDB—all running on your laptop.
How It Works
- PDF is automatically loaded from the
data/folder. - Document is split into chunks and embedded using Ollama.
- Chunks are stored in ChromaDB for fast semantic search.
- Ask questions in a Streamlit UI and get answers with source citations.
Project Structure
RAG/
├── main.py # Launches the Streamlit app
├── app.py # Streamlit UI
├── rag_client.py # RAG logic (LangChain)
├── requirements.txt # Dependencies
├── data/ # PDF and vector DB storage
└── README.md # Instructions
Install & Run Locally
# Install dependencies
pip install -r requirements.txt
# Launch the app
python main.py
The app opens at http://localhost:8501 and automatically loads your PDF from data/diet_plan.pdf.
POC Code Snippet
Here’s the core logic for querying your PDF:
# rag_client.py (simplified)
from langchain.vectorstores import Chroma
from langchain.embeddings import OllamaEmbeddings
from langchain_ollama import OllamaLLM
from langchain.chains import RetrievalQA
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
class RAGClient:
def load_pdf(self, pdf_path):
loader = PyPDFLoader(pdf_path)
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=800, chunk_overlap=100)
splits = splitter.split_documents(docs)
embeddings = OllamaEmbeddings(model="nomic-embed-text")
vectorstore = Chroma.from_documents(splits, embedding=embeddings, persist_directory="./data/chroma_db")
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 2})
llm = OllamaLLM(model="llama2")
self.qa_chain = RetrievalQA.from_chain_type(llm=llm, retriever=retriever, return_source_documents=True)
def query(self, question):
response = self.qa_chain({"query": question})
return response["result"]
And the Streamlit UI (app.py) lets you ask questions and see answers instantly:
import streamlit as st
from rag_client import RAGClient
st.title("RAG PDF Query System")
client = RAGClient()
client.load_pdf("./data/diet_plan.pdf")
query = st.text_input("Ask a question about your PDF:")
if st.button("Ask") and query:
answer = client.query(query)
st.write("Answer:", answer)
Why This Matters
Instead of generic answers, you get responses grounded in your actual data—whether it’s your diet plan, workout log, or any personal document.
- No cloud required: Runs locally, keeps your data private.
- Fast and flexible: Swap out PDFs, models, or even the vector DB (ChromaDB, FAISS, Elasticsearch) with minimal code changes.
🔹 “But Why Not Just Paste Logs into GPT?”
You can paste logs or transcripts into GPT. But that approach breaks quickly.
- Context limits → GPT can’t hold months of data.
- Dumping ≠ Retrieval → RAG fetches only what matters.
- Dynamic updates → RAG ingests fresh logs automatically.
- Efficiency → leaner prompts = faster, cheaper.
- Memory → RAG “remembers” history without re-pasting.
💪 Fitness analogy:
- Pasting = handing your coach your entire food diary every session.
- RAG = coach remembers patterns and pulls only what’s relevant to today.
🔹 Closing Thoughts
For me, RAG isn't theory. It's the foundation of something practical: a personal AI fitness agent.
Imagine asking:
- “Which muscle groups have I neglected this month?”
- “Summarize my PRs from this year.”
- “Generate next week’s workout plan based on my logs.”
For full project code, examples, and updates, see my GitHub repository: