I Hired 6 AI Agents to Be My Personal Health Team
When I decided to get serious about my health, I realized I didn’t just need a tracker.
I needed a team.
- 👉 A Nutritionist to review my meals
- 👉 A Sports Scientist to analyze my fitness data
- 👉 A Coach to plan workouts around fatigue and injuries
- 👉 A Strategist to connect diet, recovery, and performance
Hiring that team in real life? Expensive.
Asking a chatbot one question at a time? Disjointed and shallow.
So I built them.
Meet my Personal Health Agent Crew — a team of 6 specialized AI agents running locally on my laptop, collaborating through a strict sequential pipeline.
💡 Core Concept: This project is not about fitness.
It’s about demonstrating how agentic systems actually work when designed as real architectures.
🔹 Design Philosophy: MVP by Intention
This system is intentionally built as an MVP (Minimum Viable Product).
It is not optimized for:
- ❌ Scale
- ❌ Automation
- ❌ Production-grade security
- ❌ Real-time ingestion
The goal is to validate one core idea:
Can a role-based, sequential agent pipeline reason better than a single LLM prompt?
Once that hypothesis holds, everything else becomes an engineering problem.
🔹 The Core Idea: An AI Assembly Line
This is not a chatbot. It’s a pipeline.
Each agent has:
- a single responsibility
- a clear input
- a structured output
Data flows from one agent to the next — just like an assembly line in manufacturing.
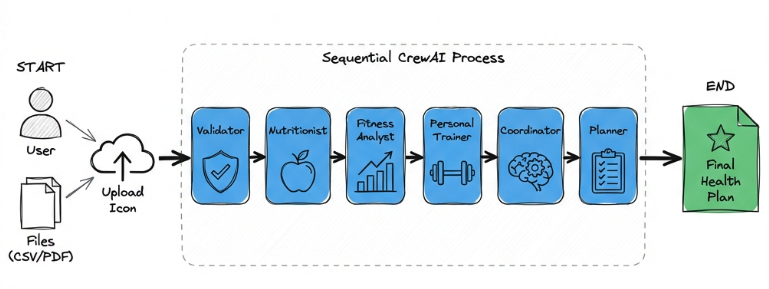
I used CrewAI with Process.sequential. This enforces:
- Agent B must wait for Agent A
- No skipping
- No parallel guessing
This gives deterministic execution order, traceability, and bounded reasoning paths.
🔹 Why Sequential (For Now)
The fully sequential pipeline is a deliberate trade-off.
Benefits
- ✅ Deterministic execution order
- ✅ Easier debugging
- ✅ Clear responsibility boundaries
- ✅ Predictable output structure
Limitations
- ⚠️ Higher latency
- ⚠️ No parallelism
- ⚠️ Not optimal for independent data streams
The Reality: Health data is stateful.
Parallel agents create contradictions.
Sequential agents create decisions.
For an MVP whose goal is understanding agent behavior, sequential wins.
🔹 Why This Is an Architecture, Not a Prompt
A common question:
“Couldn’t you just paste all this data into ChatGPT?”
Technically? Yes.
Architecturally? No.
Here’s why agents beat a single context window:
-
State Separation: Raw data, derived insight, and decisions live in separate stages. A single prompt collapses them.
-
Contract Enforcement: Agent B cannot run unless Agent A’s output validates against a schema. Chat windows have no contracts.
-
Partial Failure Containment: If the Workout Planner fails, I still have valid Nutrition and Fitness analysis. In a single prompt, one hallucination poisons everything.
The output isn’t just text.
It’s a verifiable chain of custody.
🔹 A Concrete Comparison: Prompt vs Pipeline
Single LLM Prompt Result:
“Increase protein intake and slightly reduce training volume to improve recovery.”
Agent Pipeline Result:
“Bench press stalled due to low carbohydrate intake (<50g) before high-volume sessions.
Strength plateau is nutrition-driven, not recovery-driven.
Deload unnecessary if carb timing is corrected.”
Same data.
Different outcome.
The pipeline surfaced causality, not generic advice.
🔹 Step-by-Step: How the Agents Work
Step 1: The Gatekeeper (Health Data Validator)
- Input: Raw CSVs / PDFs (MyFitnessPal logs, Apple Watch exports)
- Action: Validates schema, ranges, missing columns, date formats
- Output: Clean, validated data packet
🛑 Guardrail: If validation fails, the pipeline stops immediately.
Step 2: The Nutritionist (Meal Analyzer)
- Input: Validated food logs
- Action: Checks macro balance, micronutrient gaps, and meal timing
- Output: Nutritional profile
(e.g., “High protein, low fiber, erratic carb timing”)
Step 3: The Sports Scientist (Fitness Analyst)
- Input: Workout plan + fitness logs
- Action: Analyzes progression, heart-rate zones, recovery vs intensity
- Output: Performance report
(e.g., “Stalled strength, elevated fatigue, poor recovery days”)
Step 4: The Coach (Workout Planner)
- Input: User constraints + fitness report
- Action: Adjusts volume, schedules deloads, removes injury-risk movements
- Output: Raw workout structure
Step 5: The Strategist (Critical Step)
This is where agents outperform chatbots.
- Input: Nutrition insights + fitness analysis + workout structure
- Action: Correlates across domains to identify causality
- Authority: Can propose hypotheses, cannot directly modify plans
- Output: Integrated strategic insights
It explicitly looks for:
- 📉 Undereating vs Training Volume
- 📈 Recovery Correlations
- 🚫 Hard Constraints it cannot override (e.g., injuries)
“Bench stalled likely due to low carb intake before training.”
Step 6: The Plan Creator (Final Deliverable)
- Input: All previous outputs
- Action: Formats results for humans
- Output:
- 4-week workout calendar
- Meal plans & recipes
- Daily structure
🔹 Known Failure Modes
Great systems thinking requires acknowledging what breaks.
-
Garbage-In Cascade: A bad macro calculation creates false correlations downstream. Fix: Strict schema validation between every step.
-
Context Drift: Early agents optimize for fat loss while later agents optimize for strength. Fix: Shared memory / manager LLM (planned for v2).
-
Latency: ~45 seconds per run. Too slow for chat. Acceptable for weekly reports.
🔹 Tech Stack
- Orchestration: CrewAI
- Process Model: Sequential
- Interface: Streamlit
- Language: Python 3.10+
- Dependency Management:
uv
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
)
That one line enforces architectural discipline.
🔹 The Real Goal of This Project
This is not a medical diagnosis system. It’s a decision-support pipeline.
The real goal is to demonstrate how agent-based systems can:
- Decompose complex problems.
- Enforce responsibility boundaries.
- Reason across domains via structured handoffs.
Health is just a powerful, relatable example.
🔹 See It In Action
🔹 Open Source
The entire project is open-source and runs locally.
👉 GitHub: Personal Health Agent Repository
We don’t debug production systems with guesses. We don’t scale architectures with intuition.
So why manage health that way?
Health is the hook. Architecture is the takeaway.
When we treat decisions as pipelines rather than prompts, we move from "magic" to engineering. That is the future of agentic workflows.